|
聚类分析是常见的数据分析方法之一,主要用于市场细分、用户细分等领域。利用SPSS进行聚类分析时,用于参与聚类的变量决定了聚类的结果,无关变量有时会引起严重的错分,因此,筛选有效的聚类变量至关重要。 案例数据源:
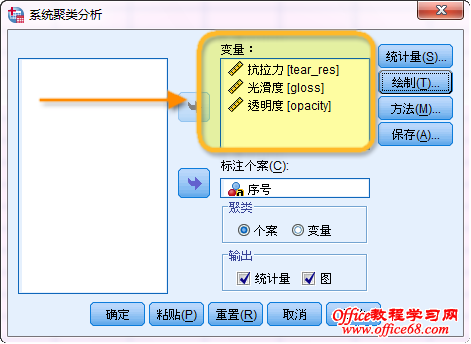
一套筛选聚类变量的方法 一、盲选 将根据经验得到的、现有的备选聚类变量全部纳入模型,暂时不考虑某些变量是否不合适。本案例采用SPSS系统聚类方法。对话框如下:
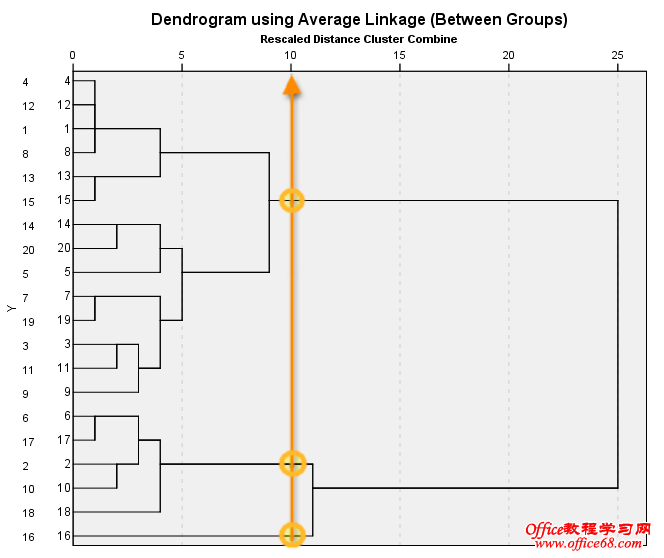
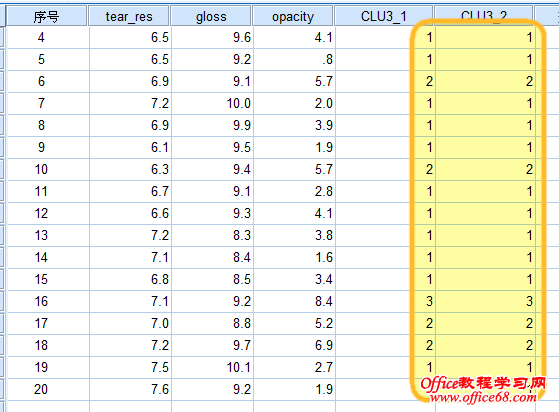
二、初步聚类 这是盲选得到的初步聚类结果,并且在数据视图我们可以看到已经自动生成了一个聚类结果变量,这个变量非常有用。
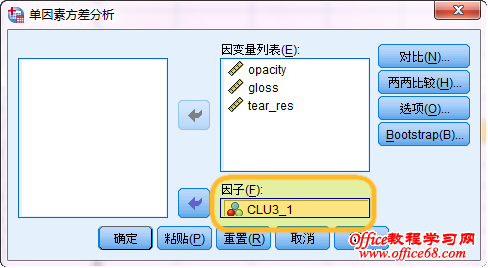
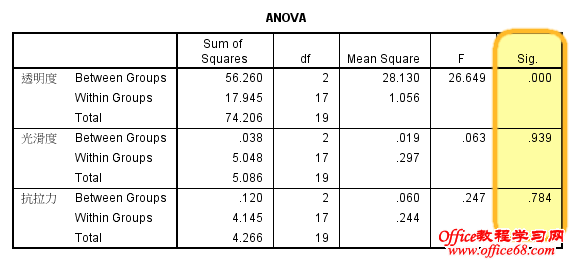
三、方差分析 是不是每一个纳入模型的聚类变量都对聚类过程有贡献?利用已经生成的初步聚类结果,我们可以用一个单因素方差分析来判断分类结果在三个变量上的差异是否显著,进而判断哪些变量对聚类是没有贡献的。
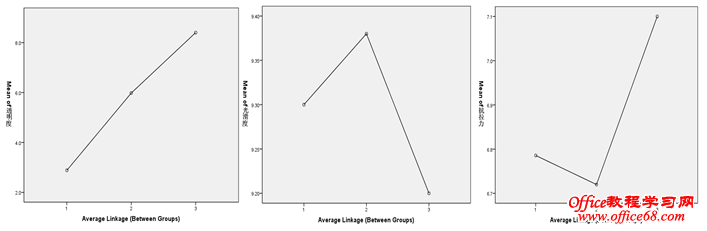
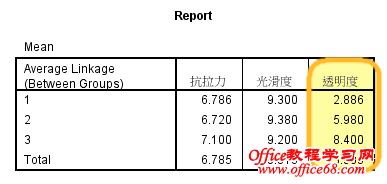
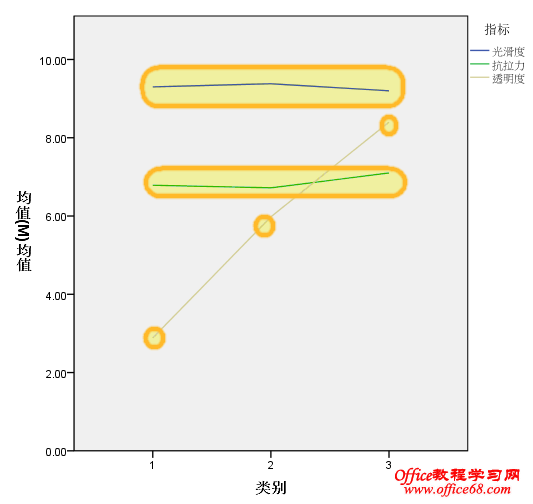
由方差分析我们很明确的得知,纳入模型的三个聚类变量,其中只有“透明度”指标在各个分类上有显著的差异,也就是说分类有效果,让每个分类的差异很大,而两外两个变量则在三个分类上没有显著差异,没有很好的类别区分度,所以,我们可以认为,这两个变量对聚类无作用或者无贡献,可考虑踢出模型。 我们还想从可视化的角度来查看和判断,单因素方差分析为我们提供了均值图,可惜,这三个图却最容易误导我们的判断,因为spss在自动生产均值图时为每一个变量单独制图,而且分配不同的纵轴坐标,导致每个图看起来都有非常大的差异,从视觉上迷惑我们做出错误的判断。 这里需要改进! 四、均值描述 为改进以上SPSS默认选项的不足之处,我们需要自己生成三个变量在不同类别上的均值,means过程可以帮助到我们。 从数字上来看,抗拉力(6.8、6.7、7.1)、光滑度(9.3、9.4、9.2)两个指标在三个类别上并没有多大的差异,而对聚类有贡献的透明度指标在不同类别上区分度非常明显。 五、多线均值图 克服纵轴刻度的方法是将这三个指标放在同一个坐标轴上进行对比,也就是制作一个多线均值图。 此时,结果已经一目了然了。 综上,我们可以将抗拉力、光滑度两个指标从模型中剔除,只留下透明度一个指标再进行聚类。 我们发现,前后两次聚类的结果一模一样,用一个指标可以代替以前三个指标的进行聚类。 我们这样做的意义何在?如果能将这些整理成为规则,形成经验,那我们就可以不用测量抗拉力和光滑度这两个指标了,你不觉得多测量两个指标成本会增加吗? 文章思路参考自:文彤老师《SPSS11高级教程》 |