|
ABBYY FineReader 12、作为一款OCR图文识别软件,可快速方便地将扫描纸质文档、PDF文件和数码相机的图像转换成可编辑、可搜索的文本,有时文本中可能会包含一些非常规的符号,此时ABBYY FineReader还能够识别吗?本文将为大家解答这一难题。
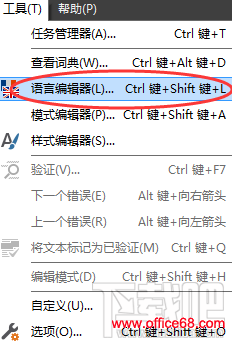
问题描述: ABBYY FineReader 12能识别包含非常规符号(象形符号、© 和 ®符号等)的文本吗? 解决问题: ABBYY FineReader 12可以训练识别所有的Unicode符号。 遵循以下说明通过ABBYY FineReader 12识别带有不常见Unicode符号的文本: 步骤一:创建新语言,将所有必要的符号添加到新语言字母表。 1、启动ABBYY FineReader 12; 2、打开工具菜单,选择语言编辑器;
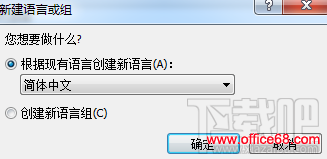
3、点击新建按钮; 4、选择需要识别的文本语言作为基础语言,然后点击确定;
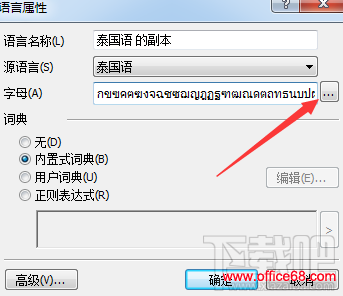
5、点击字母表框旁边的…按钮;
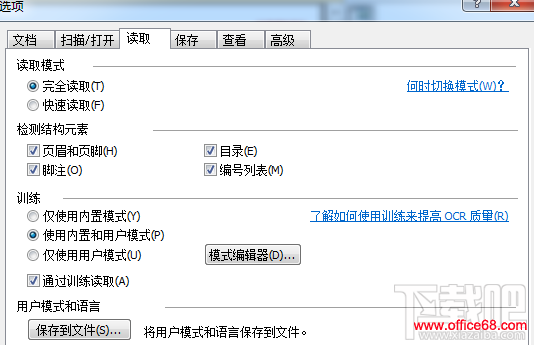
6、将所有必要的符号添加到新建语言的字母表中,然后点击确定; 7、指定新语言名称,如果有必要调整新建语言的其他参数; 8、完成编辑语言之后,点击确定。 步骤二:训练ABBYY FineReader 12识别新增的符号。 1、选择新建的语言作为当前文档的语言; 2、打开工具菜单,点击选项; 3、选择读取选项卡; 4、如果你使用的是ABBYY FineReader 11,请勾选使用内置和用户模式选项,然后选择通过训练读取选项;如果你使用的是早期版本,则勾选训练用户模式选项;
5、点击确定; 6、点击读取按钮开始识别文档,训练ABBYY FineReader 12识别新增的符号。 |