|
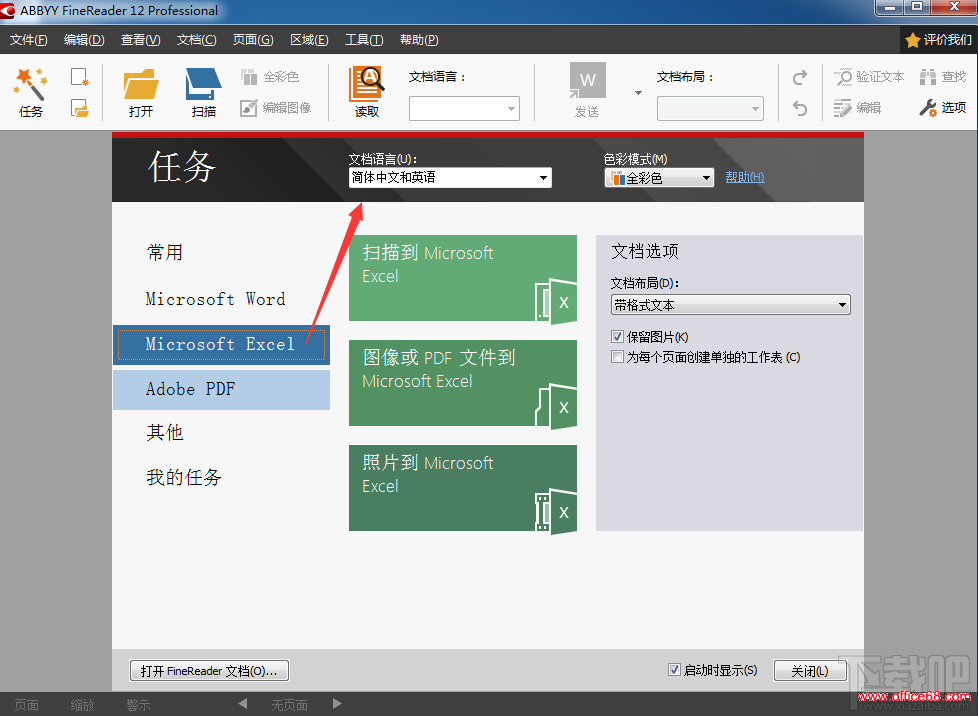
��Ϊһ��OCR��ѧ�ַ�ʶ��������ABBYY FineReader�ܹ����ٷ���ؽ�ɨ��ֽ���ĵ���PDF�ļ������������ͼ��ת���ɿɱ༭�����������ı����õ��Դ�������Ч�ʣ����Ѵ�ǰ�ķ��գ�����ʱ�������ֶ�������ļ��༭���������ҷ���һƪ����ʹ��ABBYY FineReaderʶ��ͼƬ���ı��İ��������������������ABBYY FineReader���Ч�ʵģ� ���������ղ��˼���ͼƬ��ʽ����Ӣ�Ķ��յ�ɫ�ף��Ժ����ʱ����ܻ��õ�������뵽ͨ��OCR����ѧ����ʶ��ʶ��������CAT�б��á�֮ǰ��������������λ���ж��Ƽ�ABBYY FineReader���ᵽ�������ױȵ�ʶ��Ч��������С��ţ�����˷ܲ��ѣ�Ч��ȷʵ�������������ַ���ʶ��Ƚϸߣ������£���ͼ˵������ �����ҵ�Ԥ�ȱ��������jpg��ʽ��ͼƬ����װ���°�ABBYY FineReader 12������ Ŀ�꣺��ȡͼƬ�е�Ӣ�ĺ�������������Excel��ʽ���ı��� ԭʼͼƬ
��������1������ͼƬ�е��ı�������ʾ����˴�ABBYY FineReader 12��ѡ��Microsoft Excel�
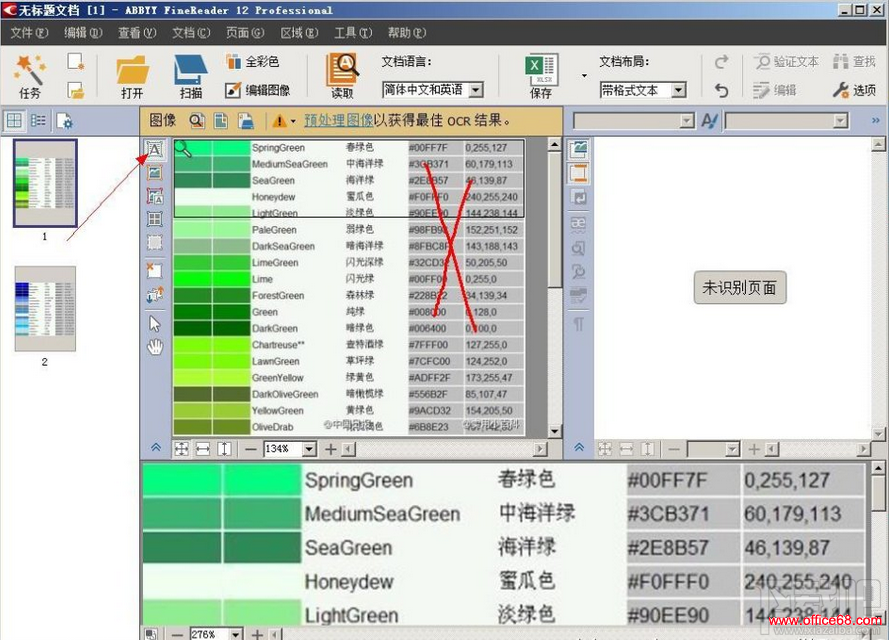
ע����������ڿ�������Ҫʶ������ԣ��������ĺ�Ӣ�ģ����Լ�ɫ��ģʽ���������ѡ��ȫ��ɫ�ͺڰ�ģʽ���ڰ�ģʽ�Ķ�ȡ�ٶ�Ҫ�Կ�һЩ�� 2��Ȼ��ѡ��“ͼ���PDF�ļ���Microsoft Excel”������Ҫʶ�������ͼƬ���������Զ���ʼʶ��Ҳ���Ե��“�ļ�”���½�һ���ĵ���Ȼ��ֱ�Ӱ�Ҫʶ���ͼƬ�Ϸŵ��������У�ͬ�����Դ���ʶ��
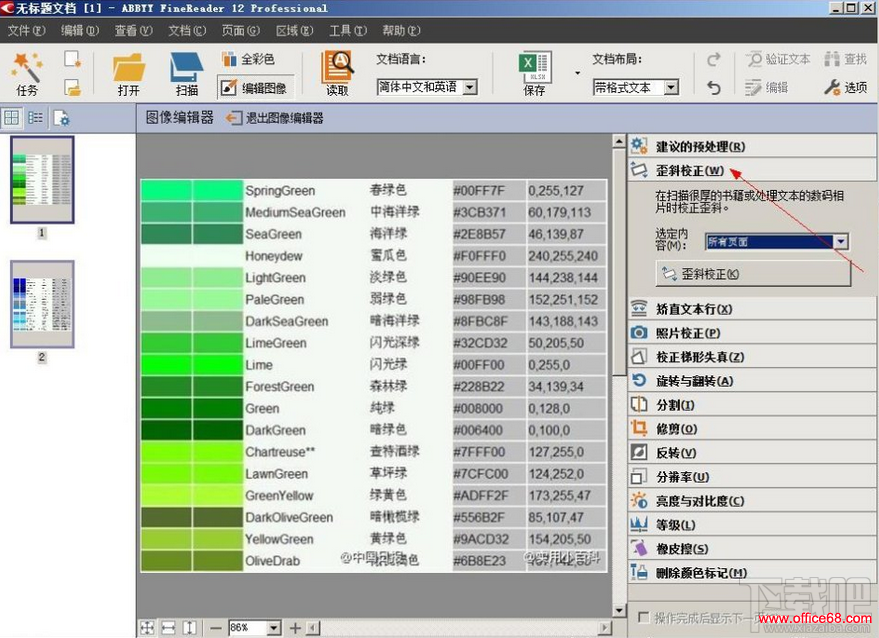
3�����ǵ�ͼƬ���ֿ��ܻ����ģ�����ı���б��ת�����ѡ��ȡ��ʶ���ȶ�ͼƬ���б༭������������湤�������“�༭ͼ��”���Ҳ�༭�����б���
4�����ȣ�Ҫ��ͼ�������бУ������ɨ���ͼƬ����������ɨ������ʾ����Ҫ����У����ͼƬ������бУ�����������ѡ��“ȫ��ҳ��”��Ȼ����“��бУ��”����ͼƬ����ת90�Ȼ�ת���ͼƬ���������ォ����ת��ת������
5����������Ҳ������Ҫ�ģ����ǵ���ͼƬ�ķֱ��ʣ���ЩͼƬģ�����壬��Ӱ������ʶ��Ч��������ɽ�ͼƬ�ķֱ�����Ϊɨ��ͼ��ķֱ��ʣ���300dpi�����ֵ�����϶���������ʶ���ˣ�Ҳ�����Զ���ֱ��ʡ�ͨ�����ѡ��ɷֱ�������ͼƬ�ķֱ��ʣ�Ҳ����ѡ����ҳ��ż��ҳ��ȫ��ҳ�棬Ϊ�˲�Ӱ��ʶ���������ѡ��“����ҳ��”��
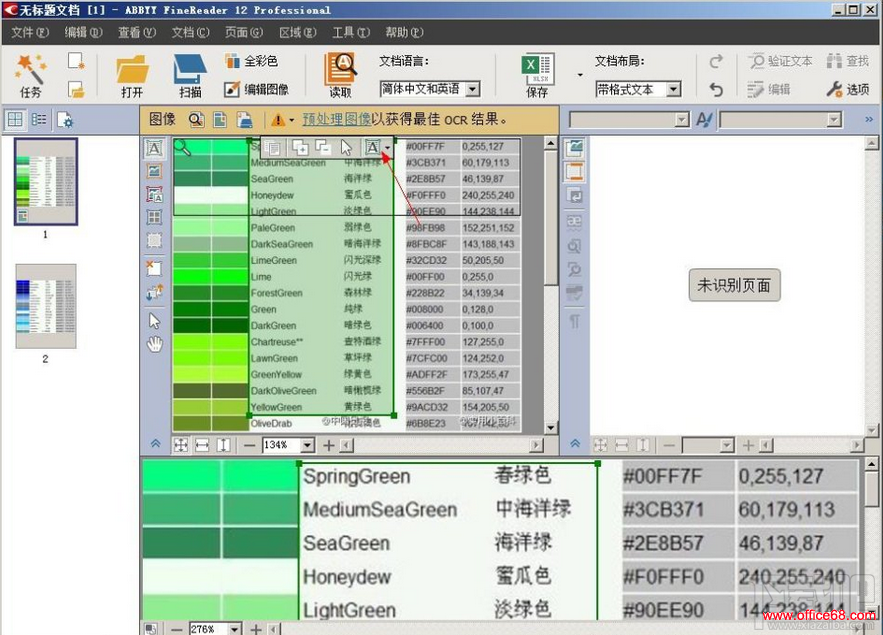
6��Ȼ��Ϳ����˳�ͼ��༭���� 7����������ֻ��Ҫ��Ӣ�Ķ��յ������ı��������ص����ݿ��Բ�����ʶ����ˣ���ѡ��Ҫʶ�����������м�һ�����Ͻǵ�“A”��ť����ѡ������Ҫʶ����ı���
8��ѡ������ı���dz��ɫ��Ȼ����ѡ�������ڵ����Ĺ�����ѡ��ť“A”���ҵ������“����”�����ʶ�����ı��ͳ����ж��յ��ı��ˣ�
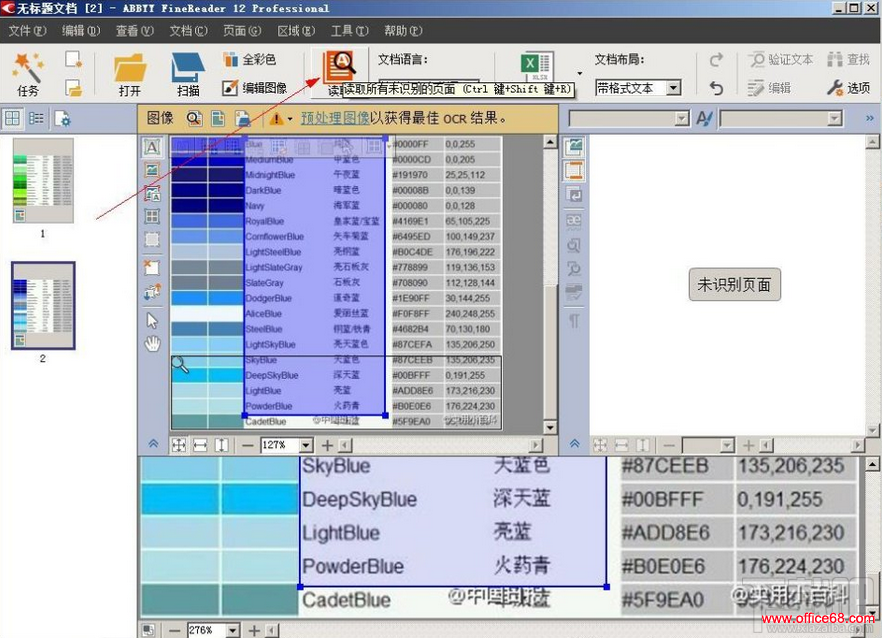
9��Ȼ������湤�������“��ȡ”ѡ���ʼʶ��
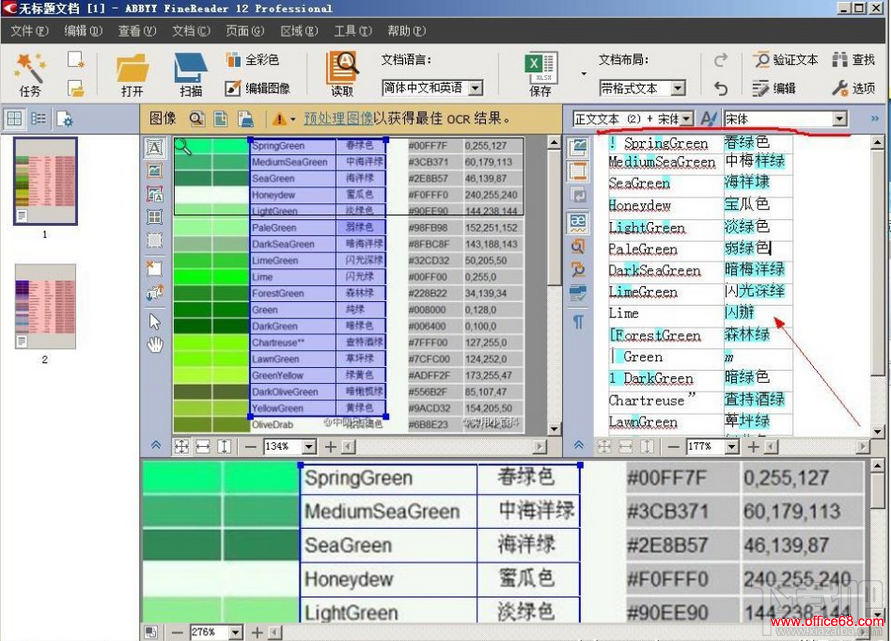
10����ͼΪʶ����Ч��ͼ�����Ҳ�һ����ʶ����ı����ݣ��ڸ���ͷ�����ɶ�ʶ����ı���ʽ�������ã����������壬�ֺš���б���Ӵֵȣ�
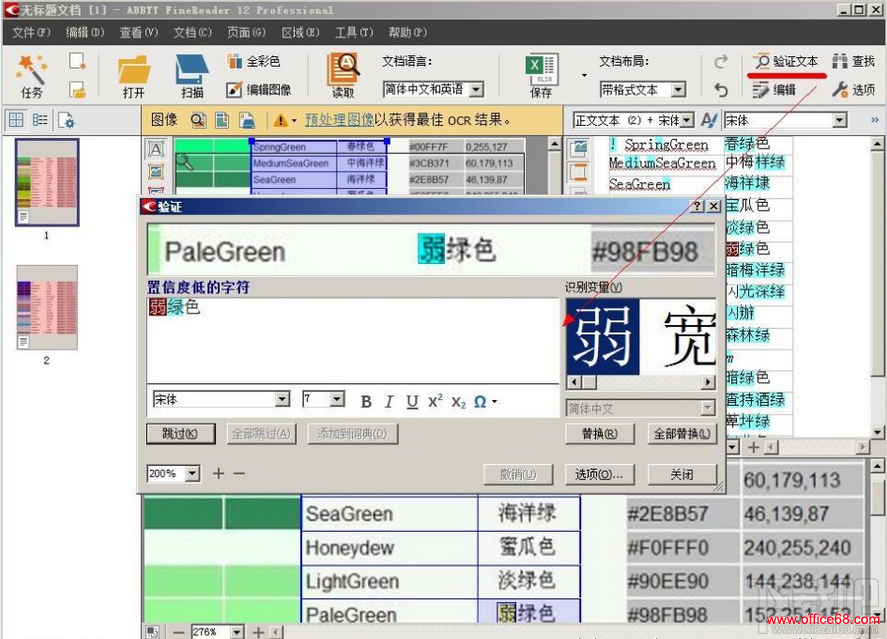
11��ʶ�����ı��У���ɫ��ʾ���ǿ��ܴ���ƴд��ʶ���������ŶȽϵ͵��ַ������δ������ֱ�ӵ��������ܻ�Ӱ���Ժ�ʹ�á���ʱ����ѡ�������“��֤�ı�”������ɫ��Dz��ֽ��б༭ȷ�ϣ�
12�����������У��ᷢ�ֱ��Ϊ��ɫ���ı���Щ��û��ƴд������ֻ���������ò��������������ֻ��Ҫ�����������ɣ�����ʶ���������֣����и����滻��FineReader�Դ����ֵ����ʾ������ȷ��ʶ�������ѡ����ȷ�����֣����“�滻”��“ȫ���滻”��Ȼ��“ȷ��”���ɣ�
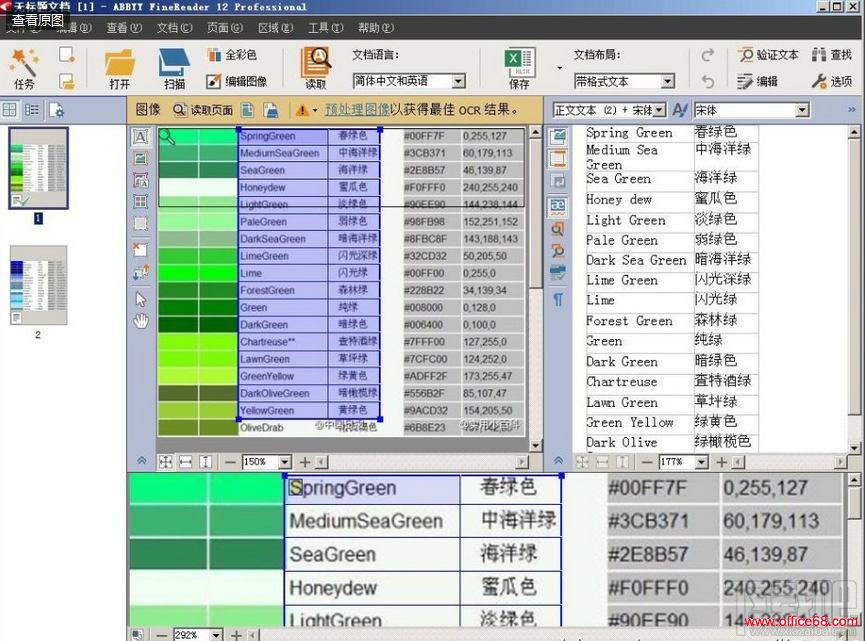
13����ͼ����֤����ı����Dz������۶��ˣ� 14��Ȼ������ı�������������ڵ�“����”��������ΪExcel��ʽ���ļ���Ĭ��״̬�£�����õ��ļ����Զ���
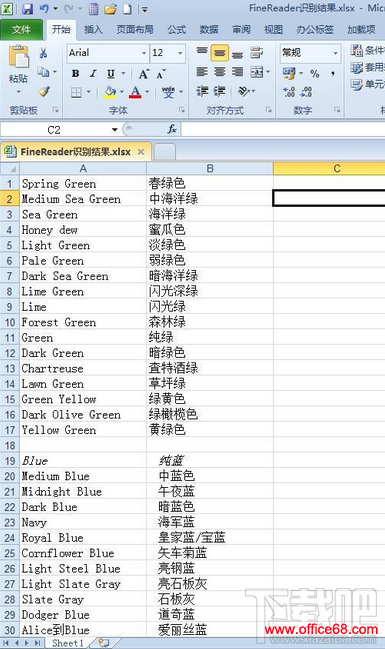
15�����ǵ�������ļ����ٴζ�������ֺŽ��е�����ʹ�俴�����������ۡ�Ȼ��Ϳ������������CAT��������������룩�����У��Ժ���ʱ��������ִ������CAT�����Զ���ʾ���Dz���ʡȥgoogle��������ѯ�Ŀ����ˣ� ���˱���ʹ��ABBYY FineReader�ķ��������Dz���ҲԾԾ�������أ� |